Referencias Bibliográficas — APA 7
1Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901.
2Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., … Zaremba, W. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374. https://doi.org/10.48550/arXiv.2107.03374
3CWE/SANS Institute. (2023). 2023 CWE top 25 most dangerous software weaknesses. MITRE Corporation. https://cwe.mitre.org/top25/archive/2023/2023_top25_list.html
4European Parliament. (2024). Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (AI Act). Official Journal of the European Union. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
5He, J., & Vechev, M. (2023). Large language models for code: Security hardening and adversarial testing. Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 1865–1879. https://doi.org/10.1145/3576915.3623180
6International Organization for Standardization. (2023). ISO/IEC 42001:2023 — Information technology — Artificial intelligence — Management system. ISO.
7Liang, J., Liu, J., & Janes, A. (2024). A survey on evaluating large language models in code generation tasks. arXiv preprint arXiv:2408.16498. https://doi.org/10.48550/arXiv.2408.16498
8Moher, D., Liberati, A., Tetzlaff, J., & Altman, D. G. (2009). Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLOS Medicine, 6(7), e1000097. https://doi.org/10.1371/journal.pmed.1000097
9National Institute of Standards and Technology. (2023). Artificial intelligence risk management framework (AI RMF 1.0) (NIST AI 100-1). U.S. Department of Commerce. https://doi.org/10.6028/NIST.AI.100-1
10Negri-Ribalta, C., Roa-Martínez, S. M., Lopezosa, C., & Codina, L. (2024). Generative AI and cybersecurity in software development: A systematic literature review. Future Internet, 16(10), 367. https://doi.org/10.3390/fi16100367
11Niu, B., Tang, X., Li, S., & Chen, J. (2023). CodexLeaks: Privacy leaks from code generation language models in GitHub Copilot. 32nd USENIX Security Symposium, 2321–2338.
12OWASP Foundation. (2023). OWASP top 10 for large language model applications: Version 1.1. https://owasp.org/www-project-top-10-for-large-language-model-applications/
13Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., … Moher, D. (2021). The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ, 372, n71. https://doi.org/10.1136/bmj.n71
14Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., & Karri, R. (2022). Asleep at the keyboard? Assessing the security of GitHub Copilot's code contributions. 2022 IEEE Symposium on Security and Privacy, 754–768. https://doi.org/10.1109/SP46214.2022.9833571
15Perry, N., Srivastava, M., Kumar, D., & Boneh, D. (2023). Do users write more insecure code with AI assistants? Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2785–2799. https://doi.org/10.1145/3576915.3623157
16Sallou, J., Durieux, T., & Panichella, A. (2024). Breaking the silence: The threats of using LLMs in software engineering. Proceedings of the 2024 ACM/IEEE 44th ICSE: New Ideas and Emerging Results, 102–106. https://doi.org/10.1145/3639476.3639762
17Sandoval, G., Pearce, H., Nys, T., Karri, R., Garg, S., & Dolan-Gavitt, B. (2023). Lost at C: A user study on the security implications of large language model code assistants. 32nd USENIX Security Symposium, 2205–2222.
18Seacord, R. C. (2013). Secure coding in C and C++ (2nd ed.). Addison-Wesley Professional.
19Tian, Z., & Chen, J. (2023). Is ChatGPT the ultimate programming assistant? How far is it? arXiv preprint arXiv:2304.11938. https://doi.org/10.48550/arXiv.2304.11938
20Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998–6008.
21GitHub. (2023). GitHub Copilot: Your AI pair programmer. https://github.com/features/copilot
22Amazon Web Services. (2023). Amazon CodeWhisperer: AI-powered coding companion. https://aws.amazon.com/codewhisperer/
23Bass, L., Clements, P., & Kazman, R. (2021). Software architecture in practice (4th ed.). Addison-Wesley Professional.
24Shafiq, S., Hussain, A., & Bhatti, S. N. (2020). Systematic literature review of security challenges in cloud computing. International Journal of Advanced Computer Science and Applications, 11(1), 371–379.
25Solaiman, I., Brundage, M., Clark, J., & Askell, A. (2019). Release strategies and the social impacts of language models. arXiv preprint arXiv:1908.09203. https://doi.org/10.48550/arXiv.1908.09203
Recursos Digitales — Imágenes y Videos Generados con IA
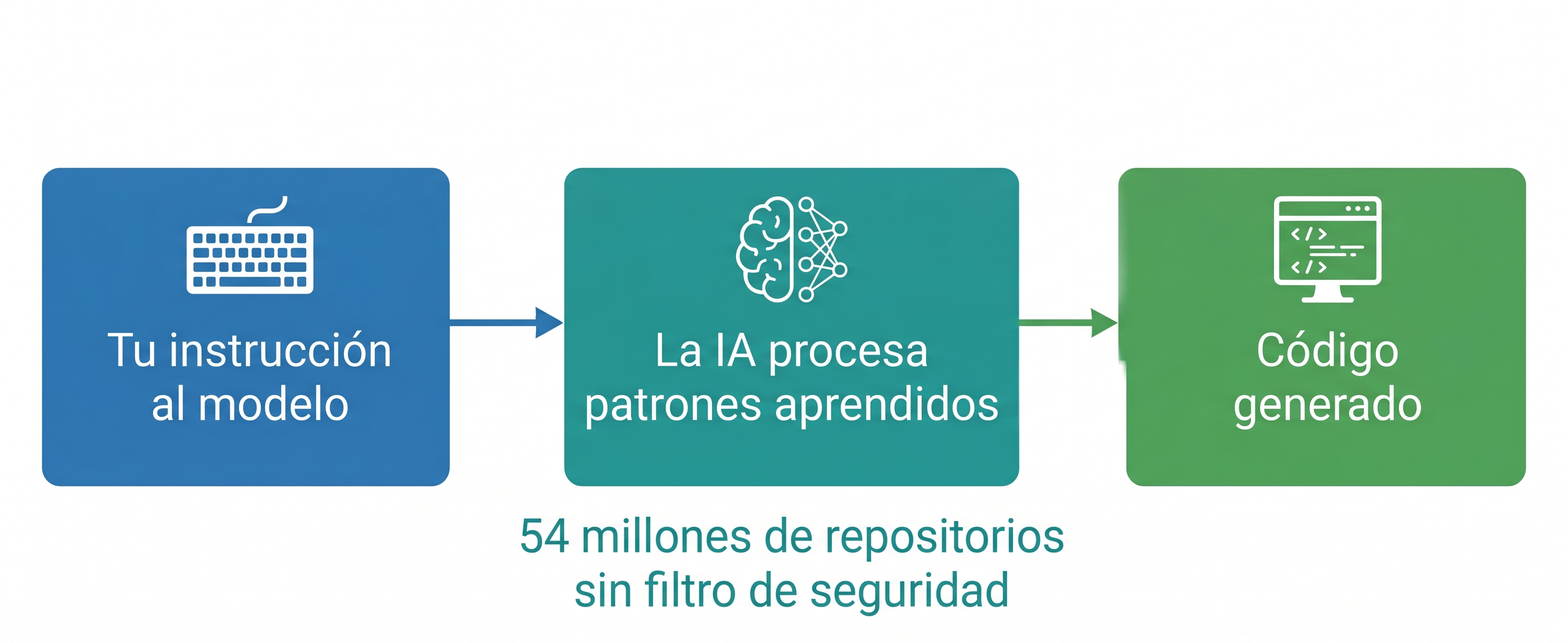
26Google. (2025). Diagrama del flujo de procesamiento de un modelo de lenguaje grande (LLM), desde el corpus de entrenamiento hasta el código generado [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
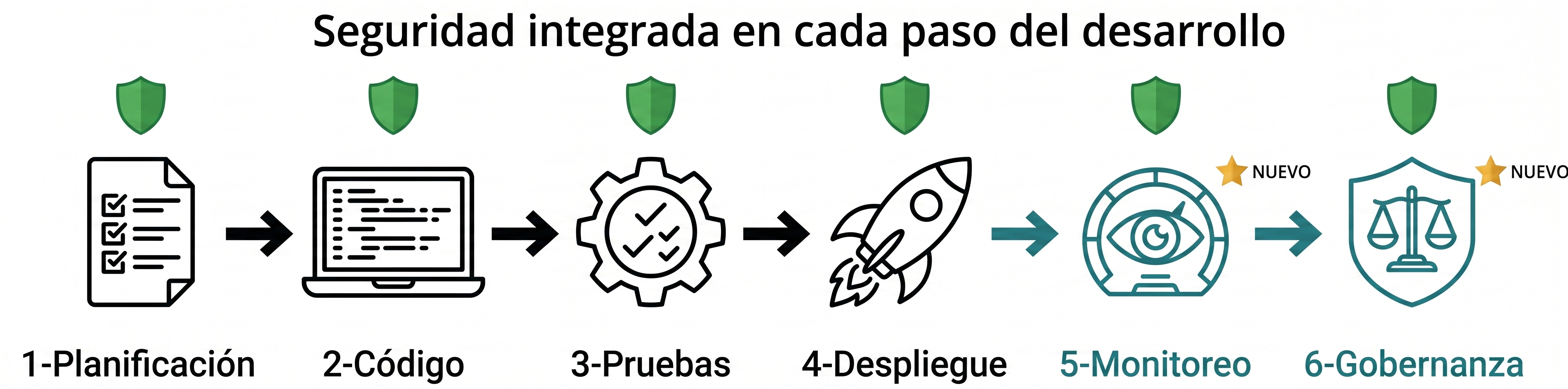
27Google. (2025). Infografía del pipeline DevSecOps de seis etapas integrado con controles específicos para proyectos con IA generativa [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
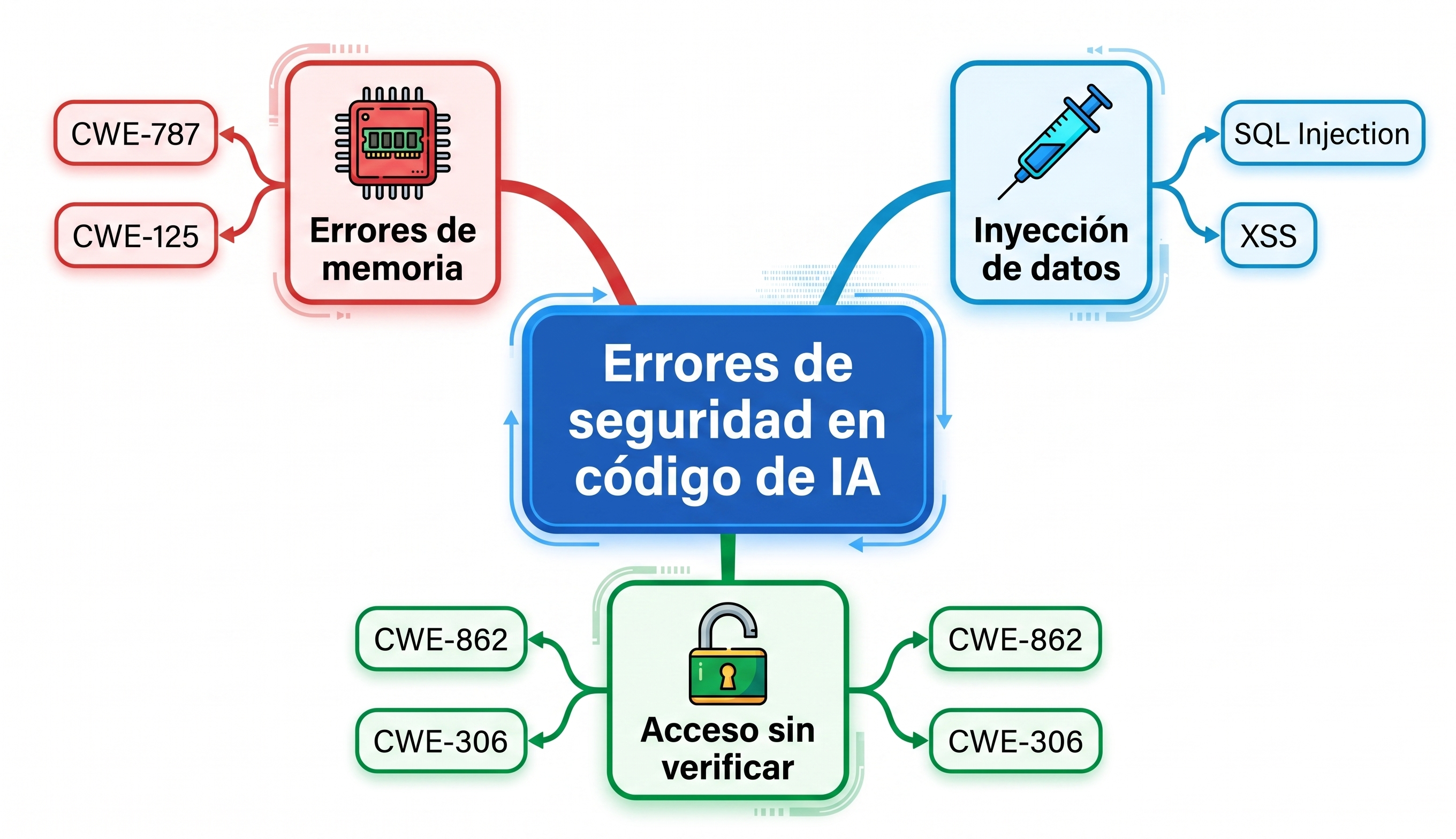
28Google. (2025). Infografía de las tres categorías principales de vulnerabilidades CWE detectadas en código generado por modelos de IA [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
29Google. (2025). Visualización de hallazgos cuantitativos clave de 38 estudios científicos sobre seguridad en código generado por IA (revisión PRISMA 2020) [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
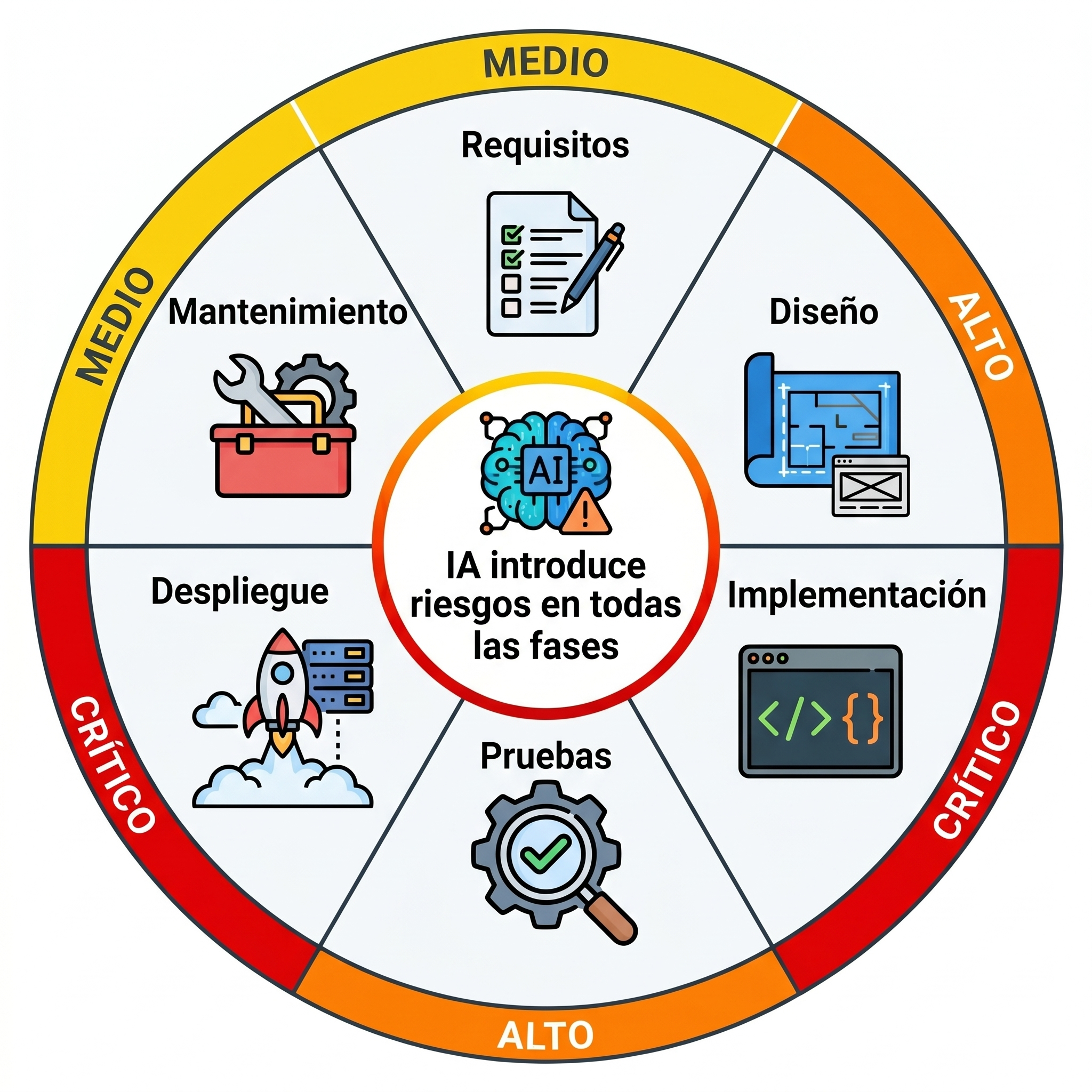
30Google. (2025). Mapa de vectores de riesgo introducidos por IA generativa en cada fase del ciclo de vida del desarrollo de software (SDLC) [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
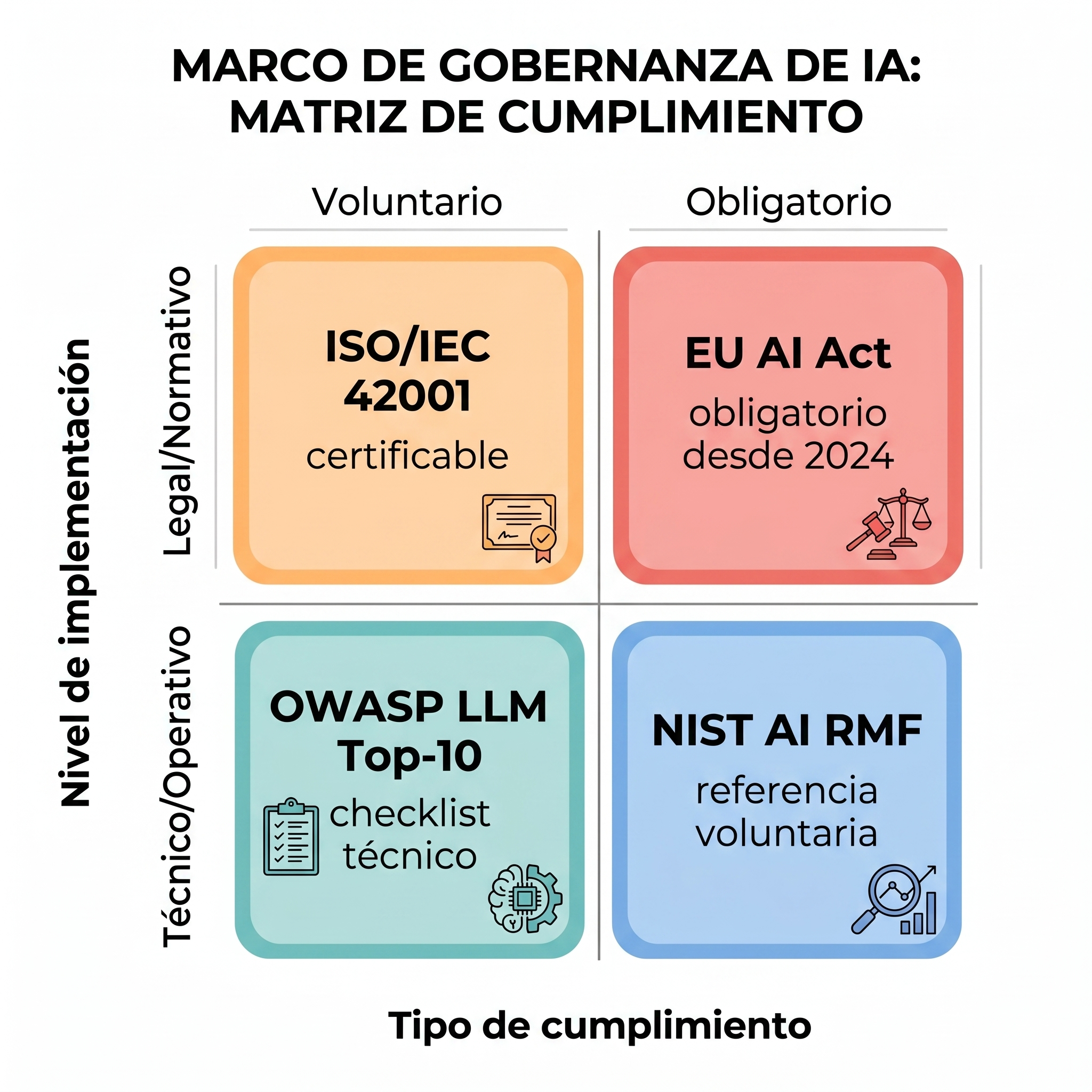
31Google. (2025). Infografía de los cuatro marcos de gobernanza y regulación para el uso responsable de inteligencia artificial en el desarrollo de software [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
32Google. (2025). Síntesis visual de los cinco hallazgos principales emergentes de la revisión sistemática PRISMA 2020 sobre riesgos de IA generativa en el SDLC [Imagen generada con inteligencia artificial]. Google Gemini (Nano Banana, versión Pro). https://gemini.google.com
33Pippit AI. (2025). Videos de presentación de pantallas ODC — Riesgos de IA Generativa en el SDLC [Videos generados con inteligencia artificial a partir de imagen y guion de texto]. Pippit. https://www.pippit.ai/
Créditos del ODC
| Rol | Responsable | Herramienta / URL | Licencia |
|---|
| Autoría y contenido | Escobar Sarmiento, Brayan Esteban · Martínez Gaitán, Edgar Andrés | — | CC BY 4.0 |
| Diseño e infografías (Figs. 1–7) | Google — Gemini Nano Banana (versión Pro) | gemini.google.com | Uso educativo — Google ToS |
| Producción de videos avatar | Pippit AI | pippit.ai | Uso educativo — Pippit ToS |
| Voz y narración | Sintetizada en Pippit AI | pippit.ai | Uso educativo — Pippit ToS |
Institución: Universidad de Cundinamarca — Facultad de Ingeniería
Programa: Especialización en Gerencia para la Transformación Digital
Director: Jhondert Alberto Jaimes Rodríguez
Año: 2025 · Revisión metodológica: PRISMA 2020
CC BY 4.0 — Atribución requerida